Producing an Ebook, Step by Step
This guide is meant to take you step-by-step through the creation of a complete Standard Ebook. While it might seem a little long, most of the text is a description of how to use various automated scripts. It can take just an hour or two for an experienced producer to produce a draft ebook for proofreading (depending on the complexity of the ebook, of course).
Our toolset is GNU/Linux-based, and producing an ebook from scratch currently requires working knowledge of the epub file format and of Unix-like systems like Mac or Linux.
Our toolset doesn’t yet work natively on Windows, but there are many ways to run Linux from within Windows, including one that is directly supported by Microsoft themselves.
If you don’t have this kind of technical expertise, you can still contribute! Check out our contributors page for details, or check out Standard Ebooks Hints and Tricks, a beginner’s guide by one of our editors.
Table of Contents
-
Set up the Standard Ebooks toolset and make sure it’s up-to-date
Standard Ebooks has a toolset that will help you produce an ebook. The toolset installs the
secommand, which has various subcommands related to creating Standard Ebooks. You can read the complete installation instructions, or if you already havepipxinstalled, run:pipx install standardebooksThe toolset changes frequently, so if you’ve installed the toolset in the past, make sure to update the toolset before you start a new ebook:
pipx upgrade standardebooksOnce the toolset is installed, you can check which version you have with:
se --version -
Select an ebook to produce
The best place to look for public domain ebooks to produce is Project Gutenberg. If downloading from Project Gutenberg, be careful of the following:
-
There may be different versions of the same publication on Gutenberg, and the best one might not be the one with the most downloads. In particular, there could be a better translation that has fewer downloads because it was produced later, or there could be a version with better HTML markup. For example, the version of Journey to the Center of the Earth with the most downloads is a less accurate translation than its less-frequently downloaded counterpart. However, you must verify that whichever version you ultimately select is not copyrighted. For example, this modern translation of Twenty Thousand Leagues Under the Seas compares favorably to the most-downloaded older translation, but because the modern translation is copyrighted (see the disclaimer at the top of the HTML file) it is ineligible to be the basis of a Standard Ebooks production.
-
Gutenberg usually offers both an HTML version and an epub version of the same ebook. Note that one is not always exactly the same as the other! A casual reader might assume that the HTML version is generated from the epub version, or the other way around; but for some reason the HTML and epub versions often differ in important ways, with the HTML version typically using fewer useless CSS classes, and including
<em>elements that the epub version is often missing.
Picking either the HTML or the epub version is fine as a starting point, but make sure to pick the one that appears to be the most accurate.
For this guide, we’ll use The Strange Case of Dr. Jekyll and Mr. Hyde, by Robert Louis Stevenson. If you search for it on Gutenberg, you’ll find that there are two versions; we will use this one rather than this one, as it is a cleaner transcription, e.g. has more modern usage of punctuation and compound words, etc.
-
-
Locate page scans of your book online
As you produce your book, you’ll want to check your work against the actual page scans. Often the scans contain formatting that is missing from the source transcription. For example, older transcriptions sometimes throw away italics entirely, and you’d never know unless you looked at the page scans. So finding page scans is essential.
Below are the three big resources for page scans. You should prefer them in this order:
Internet Archive has the widest amount of scans, with the most permissive viewing and lending policy. HathiTrust has many of the same scans as Google Books, but with a more permissive viewing policy. Google Books restricts readers based on IP address and does a poor job of implementing per-country copyright law, so people outside of the U.S. may not be able to access scans of books that are in the public domain of their country.
Each of those sources allows you to filter results by publication date, so make sure you select a maximum publication date of December 31, 1930 (in other words, everything published before January 1, 1931) to ensure they’re in the U.S. public domain.
Please keep the following important notes in mind when searching for page scans:
-
Make sure the scans you find are published before January 1, 1931. You must verify the copyright page in the page scans before proceeding.
-
Often you’ll find different editions, published at different times by different publishers, for the same book. It’s worth the effort to quickly browse through each different one to get an idea of the kinds of changes the different publishers introduced. Maybe one edition is better than another!
You’ll enter a link to the page scans you used in the
content.opfmetadata as a<dc:source>element. -
-
Contact the mailing list to pitch your production
If you’re looking to submit your ebook to Standard Ebooks, contact the mailing list to pitch the ebook you’ve selected, before you begin production. Include links to the transcription and scans you found. If you are producing this ebook for yourself, not for release at Standard Ebooks, you can skip this step.
-
Create a Standard Ebooks epub skeleton
An epub file is just a bunch of files arranged in a particular folder structure, then all zipped up. That means editing an epub file is as easy as editing a bunch of text files within a certain folder structure, then creating a zip file out of that folder.
You can’t just arrange files willy-nilly, though—the epub standard expects certain files in certain places. So once you’ve picked a book to produce, create the basic epub skeleton in a working directory.
se create-draftwill create a basic Standard Ebooks epub folder structure, initialize a Git repository within it, and prefill a few fields incontent.opf(the file that contains the ebook’s metadata).-
With the
--pg-idoptionYou can pass
se create-draftthe ID of the Project Gutenberg ebook, and it’ll try to download the ebook into./src/epub/text/body.xhtmland prefill a lot of metadata for you:se create-draft --author "Robert Louis Stevenson" --title "The Strange Case of Dr. Jekyll and Mr. Hyde" --pg-id 43 cd robert-louis-stevenson_the-strange-case-of-dr-jekyll-and-mr-hyde/If the book you’re working on was translated into English from another language, you’ll need to include the translator as well, using the
--translatorargument. (For translated books that don’t have a translator credited, you can use the name of the publisher for this argument.)se create-draft --author "Leo Tolstoy" --translator "Louise Maude" --title "Resurrection" --pg-id 1938 cd leo-tolstoy_resurrection_louise-maude/In the unusual case that your book has multiple translators, you will include each one by putting each translator’s name in quotation marks after the
--translatorargument, like so:se create-draft --author "Leo Tolstoy" --translator "Louise Maude" "Aylmer Maude" --title "The Power of Darkness" --pg-id 26661 cd leo-tolstoy_the-power-of-darkness_louise-maude_aylmer-maude/Because Project Gutenberg ebooks are produced in different ways by different people,
se create-drafthas to make some guesses and it might guess wrong. Make sure to carefully review the data it prefills into./src/epub/text/body.xhtml,./src/epub/text/colophon.xhtml, and./src/epub/content.opf.In particular, make sure that the Project Gutenberg license is stripped from
./src/epub/text/body.xhtml, and that the original transcribers in./src/epub/text/colophon.xhtmland./src/epub/content.opfare presented correctly. -
Without the
--pg-idoptionIf you prefer to do things by hand, that’s an option too.
se create-draft --author "Robert Louis Stevenson" --title "The Strange Case of Dr. Jekyll and Mr. Hyde" cd robert-louis-stevenson_the-strange-case-of-dr-jekyll-and-mr-hyde/Now that we have the skeleton up, we’ll download Gutenberg’s HTML file for Jekyll directly into
text/folder and name itbody.xhtml.wget -O src/epub/text/body.xhtml "https://www.gutenberg.org/files/43/43-h/43-h.htm"Many Gutenberg books were produced before UTF-8 became a standard, so we may have to convert to UTF-8 before we start work. First, check the encoding of the file we just downloaded. (Mac OS users, try
file -I.)file -bi src/epub/text/body.xhtmlThe output is
text/html; charset=iso-8859-1. That’s the wrong encoding!We can convert that to UTF-8 with
iconv:iconv --from-code "ISO-8859-1" --to-code "UTF-8" < src/epub/text/body.xhtml > src/epub/text/tmp mv src/epub/text/tmp src/epub/text/body.xhtml
-
-
Do a rough cleanup of the source text and perform the first commit
If you inspect the folder we just created, you’ll see it looks something like this:
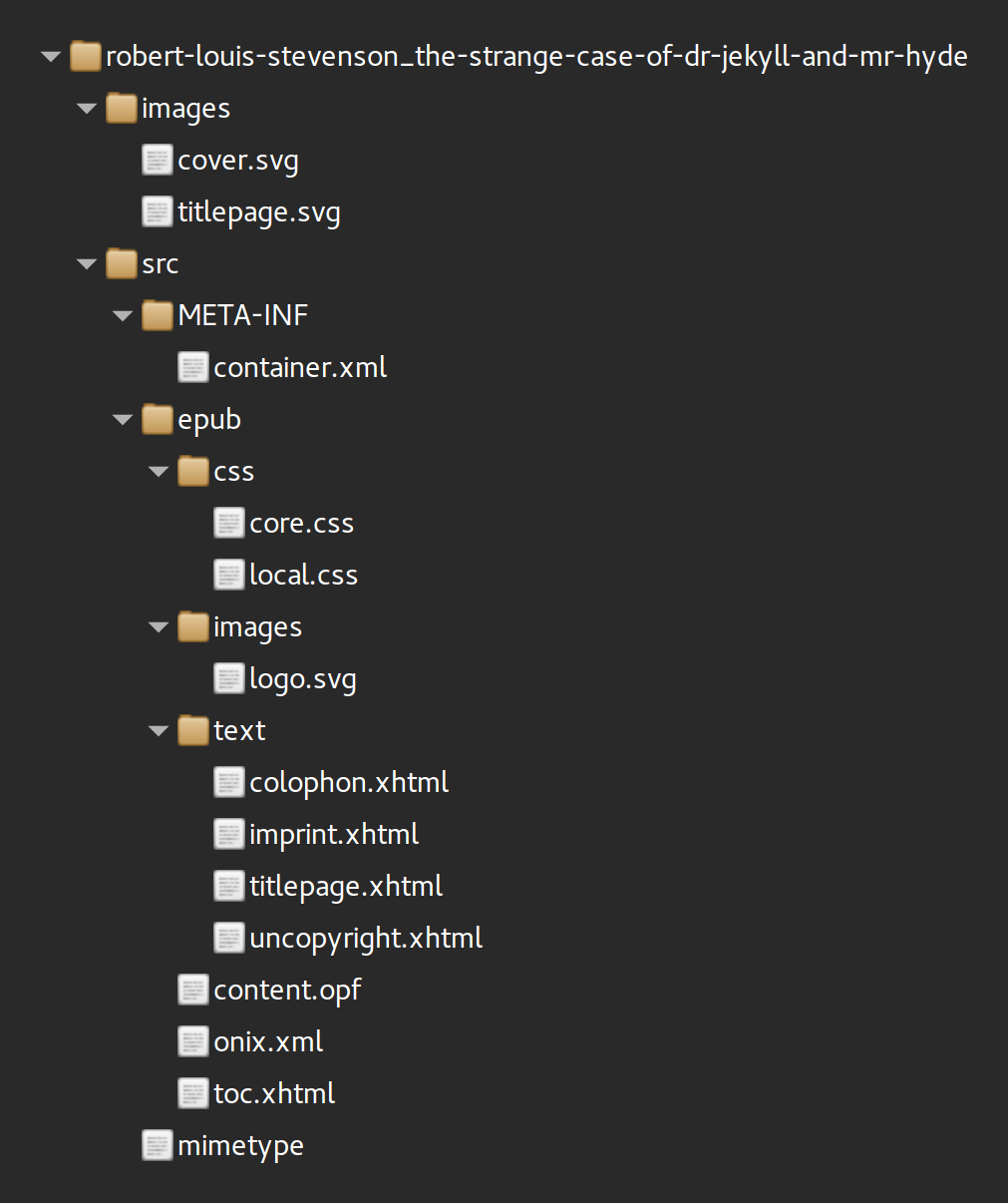
You can learn more about what the files in a basic Standard Ebooks source folder are all about before you continue.
Now that we’ve got the source text, we have to do some very broad cleanup before we perform our first commit:
-
Remove the header markup and everything, including any Gutenberg text and the work title, up to the beginning of the actual public domain text. We’ll add our own header markup to replace what we’ve removed later.
Jekyll doesn’t include front matter like an epigraph or introduction; if it did, that sort of stuff would be left in, since it’s part of the main text.
-
This edition of Jekyll includes a table of contents within the body text; remove that too. S.E. ebooks place the ToC in a separate file outside of the body text, where it can be displayed by the ereader software via UI elements.
-
Remove any footer text (e.g. “The End”), as well as any markup after the public domain text ends. This includes the Gutenberg license—but don’t worry, we’ll credit Gutenberg in the colophon and metadata later. If you invoked
se create-draftwith the--pg-idoption, then it may have already stripped the license for you and included some Gutenberg metadata.
Now our source file looks something like this:
<h2> STORY OF THE DOOR </h2> <p> Mr. Utterson the lawyer was a man of a rugged countenance that was never lighted by a smile; cold, scanty and embarrassed in discourse; backward in <!--snip all the way to the end...--> proceed to seal up my confession, I bring the life of that unhappy Henry Jekyll to an end. </p>Now that we’ve removed all the cruft from the top and bottom of the file, we’re ready for our first commit.
Each commit has an accompanying message describing the changes we are making. Please use the commit messages as they are written here in this guide as the editors rely on these messages when they review the work.
Also, try to make one commit per type of change, for example: “fixing typos in chapters 1-18” or “worked on letter formatting.”
For this first commit:
git add -A git commit -m "Initial commit" -
-
Split the source text at logical divisions
The file we downloaded contains the entire work. Jekyll is a short work, but for longer work it quickly becomes impractical to have the entire text in one file. Not only is it a pain to edit, but ereaders often have trouble with extremely large files.
The next step is to split the file at logical places; that usually means at each chapter break. For works that contain their chapters in larger “parts,” the part division should also be its own file. For example, see Treasure Island.
To split the work, we use
se split-file.se split-filetakes a single file and breaks it in to a new file every time it encounters the markup<!--se:split-->.se split-fileautomatically includes basic header and footer markup in each split file. If a book includes any front matter, like a dedication or epigraph, this is a good time to save it to its own file, so thatbody.xhtmlnow begins with the book’s first chapter.se add-fileis useful for creating skeleton files for front matter.Notice that in our source file, each chapter is marked with an
<h2>element. We can use that to our advantage and save ourselves the trouble of adding the<!--se:split-->markup by hand:perl -pi -e 's|<h2|<!--se:split--><h2|g' src/epub/text/body.xhtmlNow that we’ve added our markers, we split the file.
se split-fileputs the results in our current directory and conveniently names them by chapter number.se split-file src/epub/text/body.xhtml mv chapter* src/epub/text/Once we’re happy that the source file has been split correctly, we can remove it.
rm src/epub/text/body.xhtml -
Clean up the source text and perform the second commit
If you open up any of the chapter files we now have in the
src/epub/text/folder, you’ll notice that the code isn’t very clean. Paragraphs are split over multiple lines, indentation is all wrong, and so on.If you try opening a chapter in a web browser, you’ll also likely get an error if the chapter includes any HTML entities, like
—. This is because Gutenberg uses plain HTML, which allows entities, but epub uses XHTML, which doesn’t.We can fix all of this pretty quickly using
se clean.se cleanaccepts as its argument the root of a Standard Ebook directory. We’re already in the root, so we pass it..se clean .Finally, we have to do a quick runthrough of each file by hand to cut out any lingering Gutenberg markup that doesn’t belong. In Jekyll, notice that each chapter ends with some extra empty
<div>s and<p>s. These were used by the original transcriber to put spaces between the chapters, and they’re not necessary anymore, so remove them before continuing.Now our chapter 1 source looks like this:
<?xml version="1.0" encoding="utf-8"?> <html xmlns="http://www.w3.org/1999/xhtml" xmlns:epub="http://www.idpf.org/2007/ops" epub:prefix="z3998: http://www.daisy.org/z3998/2012/vocab/structure/, se: https://standardebooks.org/vocab/1.0" xml:lang="en-US"> <head> <title>Chapter 1</title> <link href="../css/core.css" rel="stylesheet" type="text/css"/> <link href="../css/local.css" rel="stylesheet" type="text/css"/> </head> <body epub:type="bodymatter z3998:fiction"> <section id="chapter-1" epub:type="chapter"> <h2>STORY OF THE DOOR</h2> <p>Mr. Utterson the lawyer was a man of a rugged countenance...</p> <!--snip all the way to the end...--> <p>"With all my heart," said the lawyer. "I shake hands on that, Richard."</p> </section> </body> </html>If you look carefully, you’ll notice that the
<html>element has thexml:lang="en-US"attribute, even though our source text uses British spelling! We have to change thexml:langattribute for the source files to match the actual language, which in this case is en-GB. Let’s do that now:perl -pi -e "s|en-US|en-GB|g" src/epub/text/chapter*Note that we don’t change the language for the metadata or boilerplate files, like
colophon.xhtml,imprint.xhtml, ortitlepage.xhtml. Those must always be in American spelling, so they’ll always have the en-US language tag.Once the file split and cleanup is complete, you can perform your second commit.
git add -A git commit -m "Split files and clean" -
Typogrify the source text and perform the corresponding commit(s)
Now that we have a clean starting point, we can start getting the real work done.
se typogrifycan do a lot of the heavy lifting necessary to bring an ebook up to Standard Ebooks typography standards.Like
se clean,se typogrifyaccepts as its argument the root of a Standard Ebook directory.se typogrify .Among other things,
se typogrifydoes the following:-
Converts straight quotes to curly quotes;
-
Adds no-break spaces where appropriate for some common abbreviations;
-
Normalizes ellipses;
-
Normalizes spacing in em-, en-, and double-em-dashes, as well as between nested quotation marks, and adds word joiners.
While
se typogrifydoes a lot of work for you, each ebook is totally different so there’s almost always more work to do that can only be done by hand. However, you will do a third commit first, to put the automated changes in a separate commit from any manual changes.git add -A git commit -m "Typogrify"As an example of manual changes that might be needed, in Jekyll, you’ll notice that the chapter titles are in all caps. The S.E. standard requires chapter titles to be in title case, and
se titlecasecan do that for us.se titlecaseaccepts a string as its argument, and outputs the string in title case.Typography checklist
There are many things that
se typogrifyisn’t well suited to do automatically. Check the Typography section of the SEMoS to see exactly how to format the work. Below is a brief, but incomplete, list of common issues that arise in ebooks:-
Elision.
’(i.e.,’) is used for elided letters in a word.se typogrifyoften gets this wrong, and you need to review your ebook by hand to ensure it didn’t insert‘(‘) instead.se interactive-replace --ignore-case "(\s)‘([a-z])" "\1’\2" src/epub/text/* -
Coordinates. Use the prime and double prime glyphs for coordinates.
se interactive-replace "([0-9]+)’" "\1′" src/epub/text/*se interactive-replace "([0-9]+)”" "\1″" src/epub/text/* -
Sometimes
se typogrifydoesn’t close quotation marks near em-dashes correctly.Use this regex to find incorrectly closed quotation marks near em-dashes:
—[’”][^<\s] -
Commas and periods should generally be inside quotation marks, not outside. Use this command to find and replace them:
se interactive-replace "([’”])([,.])" "\2\1" src/epub/text/*When using this command, be careful to distinguish between the use of
’as a quotation mark and its use in elision or as part of a plural possessive (i.e.s’).Correct change: “Let’s have a game of ‘noses’, lads!”➔“Let’s have a game of ‘noses,’ lads!”Incorrect change: This wood now is not mine, but the peasants’.➔This wood now is not mine, but the peasants.’ -
Non-breaking hyphens are used when a word is stretched out for effect.
Although it will produce a lot of false positives, this regex can help you find stretched words:
(?i)([a-z])-\1
The fourth commit
Once you’ve searched the work for the common issues above, if any manual changes were necessary, you should perform the fourth commit.
git add -A git commit -m "Manual typography changes" -
-
Check for transcription errors
Transcriptions often have errors, because the O.C.R. software might confuse letters for other, more unusual characters, or because the ebook’s character set got mangled somewhere along the way from the source to your repository. You’ll find most transcription errors when you proofread the text, but right now you use the
se find-unusual-characterstool to see a list of any unusual characters in the transcription. If the tool outputs any, check the source to make sure those characters aren’t errors.se find-unusual-characters .If any errors had to be corrected, a commit is needed as well.
git add -A git commit -m "Correct transcription errors" -
Convert footnotes to endnotes
Works often include footnotes, either added by an annotator or as part of the work itself. Since ebooks don’t have a concept of a “page,” there’s no place for footnotes to go. Instead, we convert footnotes to a single endnotes file, which will provide popup references in the final epub.
The endnotes file and the format for endnote links are standardized in the SEMoS.
You can add a template of an endnotes file using:
se add-file endnotes .If you find that you accidentally mis-ordered an endnote, never fear!
se shift-endnoteswill allow you to quickly rearrange endnotes in your ebook.If any footnotes were present and moved to endnotes, do another commit.
git add -A git commit -m "Move footnotes to endnotes"Jekyll doesn’t have any footnotes or endnotes, so we skip this step.
-
Add a list of illustrations
If a work has illustrations besides the cover and title pages, we include a “list of illustrations” at the end of the book, after the endnotes but before the colophon. The LoI file is also standardized.
If you created an LoI, do a corresponding commit.
git add -A git commit -m "Add LoI"Jekyll doesn’t have any illustrations, so we skip this step.
-
Convert British quotation to American quotation
If the work you’re producing uses British quotation style (single quotes for dialog and other outer quotes versus double quotes in American), we have to convert it to American style. We use American style in part because it’s easier to programmatically convert from American to British than it is to convert the other way around. Skip this step if your work is already in American style.
se british2americanattempts to automate the conversion. Your work must already be typogrified (one of the previous steps in this guide) for the script to work.se british2american .While
se british2americantries its best, thanks to the quirkiness of English punctuation rules it’ll invariably mess some stuff up. Proofreading is required after running the conversion.After you’ve run the conversion, do another commit.
git commit -am "Convert from British-style quotation to American style" -
Add semantics
Part of producing a book for Standard Ebooks is adding meaningful semantics wherever possible in the text.
se semanticatedoes a little of that for us—for example, for some common abbreviations—but much of it has to be done by hand.Adding semantics means two things:
-
Using meaningful elements to mark up the work:
<em>when conveying emphatic speech instead of<i>,<abbr>to wrap abbreviations,<section>to mark structural divisions, using thexml:langattribute to specify the language of a word or passage, and so on. -
Using the epub3 semantic inflection language to add deeper meaning to elements.
Currently we use a mix of epub3 structural semantics, z3998 structural semantics for when the epub3 vocabulary isn’t enough, and our own S.E. semantics for when z3998 isn’t enough.
Use
se semanticateto do some common cases for you:se semanticate .se semanticatetries its best to correctly add semantics, but sometimes it’s wrong. For that reason you should review the changes it made before accepting them:git difftoolAs we did with
typogrify, we want the automated portion of adding semantics to be in its own commit. After runningsemanticate, do another commit.git commit -am "Semanticate"Beyond that, adding semantics is mostly a by-hand process. See the SEMoS for a detailed list of the kinds of semantics we expect in a Standard Ebook.
Here’s a short list of some of the more common semantic issues you’ll encounter:
-
Semantics for italics:
<em>should be used for when a passage is emphasized, as in when dialog is shouted or whispered.<i>is used for all other italics, with the appropriate semantic inflection. Older transcriptions usually use just<i>for both, so you must change them manually if necessary. Use the following command to check instances of italics:grep --recursive --line-number --extended-regexp "<i|<em" src/epub/text/*.xhtml -
Semantics rules for abbreviations. Abbreviations should always be wrapped in the
<abbr>element and with the correctepub:typeattribute.Specifically, see the typography rules for initials. Wrap people’s initials in
<abbr epub:type="z3998:given-name">. This command helps wrap initials:se interactive-replace '(?<!<abbr[^<]*?>)([A-Z]\.(\s?[A-Z]\.)*)(?!</abbr>|”)' '<abbr epub:type="z3998:given-name">\1</abbr>' src/epub/text/* -
Typography rules for times. Wrap a.m. and p.m. in
<abbr>and add a no-break space between digits and a.m. or p.m. -
Words or phrases in foreign languages should always be marked up with
<i xml:lang="TAG">, where TAG is an IETF language tag. This website can help you look them up. If the text uses fictional or unspecific languages, use thex-prefix and make up a subtag yourself. -
Semantics for poetry, verse, and song: Many Gutenberg productions use the
<pre>element to format poetry, verse, and song. This is, of course, semantically incorrect. See the Poetry section of the SEMoS for templates on how to semantically format poetry, verse, and song.
Additionally, after adding semantics, you should check for any remaining typography issues:
-
Text in all caps. Text in all caps is almost never correct, and should either be converted to lowercase with the
<em>element (for spoken emphasis),<strong>(for extreme spoken emphasis), or<b>(for unsemantic small caps, like in storefront signs).Use the following command to check for instances of all caps:
se xpath "//p//text()[re:test(., '[A-Z]{2,}') and not(contains(., 'OK') or contains(., 'SOS')) and not(parent::abbr or parent::var or parent::a or parent::*[contains(@epub:type, 'z3998:roman')])]" src/epub/text/*.xhtml
After you’ve added semantics according to the SEMoS, do another commit.
git commit -am "Manually add additional semantics" -
-
Modernize spelling and hyphenation
Many older works use outdated spelling and hyphenation that would distract a modern reader. (For example,
to-nightinstead oftonight).se modernize-spellingautomatically removes hyphens from words that used to be compounded, but aren’t anymore in modern English spelling.Do run this tool on prose. Don’t run this tool on poetry.
se modernize-spelling .After you run the tool, you must check what the tool did to confirm that each removed hyphen is correct. Sometimes the tool will remove a hyphen that needs to be included for clarity, or one that changes the meaning of the word, or it may result in a word that just doesn’t seem right. Re-introducing a hyphen is OK in these cases.
Here’s a real-world example of where
se modernize-spellingmade the wrong choice: In The Picture of Dorian Gray chapter 11, Oscar Wilde writes:He possessed a gorgeous cope of crimson silk and gold-thread damask…
se modernize-spellingwould replace the dash ingold-threadso that it readsgoldthread. Wellgoldthreadis an actual word, which is why it’s in our dictionary, and why the script makes a replacement—but it’s the name of a type of flower, not a golden fabric thread! In this case,se modernize-spellingmade an incorrect replacement, and we have to change it back.Modernize spacing in select words
Over time, spelling of certain common two-word phrases has evolved into a single word. For example,
someoneused to be the two-word phrasesome one, which would read awkwardly to modern readers. This is our chance to modernize such phrases.Note that we use
se interactive-replaceto perform an interactive search and replace, instead of doing a global, non-interactive search and replace. This is because some phrases caught by the regular expression should not be changed, depending on context. For example,some onein the following snippet from Anton Chekhov’s short fiction should not be corrected:He wanted to think of some one part of nature as yet untouched...
Use each of the following commands to correct a certain set of such phrases:
-
some one ➔ someone
Correct change: She asked some one on the street.➔She asked someone on the street.Incorrect change: But every clever crime is founded ultimately on some one quite simple fact.➔But every clever crime is founded ultimately on someone quite simple fact.se interactive-replace "\b([Ss])ome one" "\1omeone" src/epub/text/* -
any one ➔ anyone
Correct change: “Any one else on this floor?” he asked.➔“Anyone else on this floor?” he asked.Incorrect change: It is not easy to restore lost property to any one of them.➔It is not easy to restore lost property to anyone of them.se interactive-replace "\b([Aa])ny one" "\1nyone" src/epub/text/* -
every one ➔ everyone
Correct change: He was furiouswj—furious with himself, furious with every one.➔He was furiouswj—furious with himself, furious with everyone.Incorrect change: I’m sure we missed ten for every one we saw.➔I’m sure we missed ten for everyone we saw.se interactive-replace '(?<![Ee]ach and )([Ee])very one(?!\s+of)' "\1veryone" src/epub/text/* -
any way ➔ anyway
Correct change: Not all, of course, but any way it is much better than the life here.➔Not all, of course, but anyway it is much better than the life here.Incorrect change: And I’m not at fault in any way, and there’s no need for me to suffer.➔And I’m not at fault in anyway, and there’s no need for me to suffer.se interactive-replace '(?<!in\s+)\b([Aa])ny way(?!\s+(?:of|to))' "\1nyway" src/epub/text/* -
with out ➔ without
Correct change: Send with out delay warrant of arrest to Bombay.➔Send without delay warrant of arrest to Bombay.Incorrect change: “Who on earth are you talking with out there?” called the querulous voice.➔“Who on earth are you talking without there?” called the querulous voice.se interactive-replace "\b([Ww])ith out\b([^-])" "\1ithout\2" src/epub/text/*
After you’ve reviewed the changes, create an
[Editorial]commit. This type of commit is important, because it gives purists an avenue to reverse these changes back to the original text.git commit -am "[Editorial] Modernize hyphenation and spelling"Manual spelling changes
You can and should update spelling of other words that you come across during proofreading, with the following caveats:
-
We modernize sound-alike spelling, not grammar or word usage. Thus, updating
maktomakeis OK, but changingmakethtomakesis not. -
We usually don’t bother with adding or removing dashes or spaces from compound words, other than what
se modernize-spellingdoes. For exampledining-roommight read more modern with a space, but dashes and spaces are inconsistent over a large number of words and it’s too much work to keep a master list. -
Don’t change spelling from en-US to en-GB or vice-versa, even to align with a book’s “language.” Having mixed spelling in a book was common and not something we standardize. This article provides a good overview of the differences between British and U.S. English.
-
If, after having run
se modernize-spelling, you find a hyphenated compound word that appears in Merriam-Webster's basic online search results without a hyphen, then you can make an Editorial change to update it. Please also let us know so that we can updatese modernize-spelling. -
If you find an archaic word that you think should be modernized, a good way to check is with a Google Ngram search. Remember to select either American English or British English!
Any manual spelling changes made must be in an
[Editorial]commit, e.g.git commit -m "[Editorial] mak -> make" -
-
Check for consistent diacritics
Sometimes during transcription or even printing, instances of some words might have diacritics while others don’t. For example, a word in one chapter might be spelled
châlet, but in the next chapter it might be spelledchalet.se find-mismatched-diacriticslists these instances for you to review. Spelling should be normalized across the work so that all instances of the same word are spelled in the same way. Keep the following in mind as you review these instances:-
In modern English spelling, many diacritics are removed (like
chalet). If in doubt, ask your assigned project manager. -
Even though diacritics might be removed in English spelling, they may be preserved in non-English text, or in proper names.
He visited the hotel called the Châlet du Nord.
se find-mismatched-diacritics .If any changes had to be made, a corresponding editorial commit should be done as well.
git commit -am "[Editorial] Correct mismatched diacritics" -
-
Check for consistent dashes
Similar to
se find-mismatched-diacritics,se find-mismatched-dasheslists instances where a compound word is spelled both with and without a dash. Dashes in words should be normalized to one or the other style.se find-mismatched-dashes .If corrections were made, another commit is needed.
git commit -am "[Editorial] Correct mismatched dashes" -
Set
<title>elementsAfter you’ve added semantics and correctly marked up section headers, it’s time to update the
<title>elements in each chapter to match their expected values.The
se build-titletool takes a well-marked-up section header from a file, and updates the file’s<title>element to match:se build-title .Once you’ve verified the titles look good, commit:
git commit -am "Add titles" -
Build the manifest and spine
In
content.opf, the manifest is a list of all of the files in the ebook. The spine is the reading order of the various XHTML files.se build-manifestandse build-spinewill create these for you. Run these on our source directory and they’ll update the<manifest>and<spine>elements incontent.opf.Since this is the first time we’re editing
content.opf, we’re OK with replacing both the manifest and spine elements with a guess at the correct contents.se build-manifest . se build-spine .The manifest is already in the correct order and doesn’t need to be edited. The spine, however, will have to be reordered to be in the correct reading order. Once you’ve done that, commit!
git commit -am "Add manifest and spine" -
Build the table of contents
With the spine in the right order, we can now build the table of contents.
The table of contents is a structured document that lets the reader easily navigate the book. In a Standard Ebook, it’s stored outside of the readable text directory with the assumption that the reading system will parse it and display a navigable representation for the user.
Use
se build-tocto generate a table of contents for this ebook.se build-toc .Review the generated ToC in
./src/epub/toc.xhtmlto make surese build-tocdid the right thing.se build-tocis a valuable tool to discover structural problems in your ebook. If an entry is arranged in a way you weren’t expecting, perhaps the problem isn’t withse build-toc, but with your XHTML code—be careful!It’s very rare that
se build-tocmakes an error given a correct ebook structure, but if it does, you may have to make changes to the table of contents by hand.Once you’re done, commit:
git commit -am "Add ToC" -
Clean and lint
Before you build the ebook for proofreading, it’s a good idea to check the ebook for some common problems you might have run into during production.
First, run
se cleanone more time to both clean up the source files, and to alert you if there are XHTML parsing errors. Even though we ranse cleanbefore, it’s likely that in the course of production the ebook got into less-than-perfect markup formatting. Remember you can runse cleanas many times as you want—it should always produce the same output.se clean .Now, run
se lint. If your ebook has any problems, you’ll see some output listing them. We’re expecting some errors, because we haven’t added a cover or completed the colophon or metadata. You can ignore those errors for now, because we’ll fix them in a later step. But, you do want to correct any fixable errors related to your previous work.se lint .If there are no errors,
se lintwill complete silently—but again, at this stage we’re expecting to see some errors because our ebook isn’t done yet.When correcting the errors, be sure to keep each commit to a single unit of work, and to signify what is being changed in the commit message, not what prompted the change. Lint can identify a wide variety of issues, and they should not all be lumped together in the same commit, nor should the commit message be something like “Fix lint errors.” Instead, “Fix transcription typos identified by lint” or “Correct header semantics identified by lint,” and so forth, would be more appropriate.
-
Build and proofread, proofread, proofread!
At this point, our ebook is still missing some important things—a cover, the colophon, and some metadata—but the actual book is in a state where we can start proofreading. We complete a cover-to-cover proofread now, even though there’s still work to be done on the ebook, because once you’ve actually read the book, you’ll have a better idea of what kind of cover to select and what to write in the metadata description.
se buildwill create a usable epub file for transfer to your ereader. We’ll run it with the--kindleand--koboflag to build a file for Kindles and Kobos too. If you won’t be using a Kindle or Kobo, you can omit those flags.se build --output-dir=$HOME/dist/ --kindle --kobo .If there are no errors, we’ll see five files in the brand-new
~/dist/folder in our home directory:-
the-strange-case-of-dr-jekyll-and-mr-hyde_advanced.epubis the zipped up version of our source. Unfortunately most ebook readers don’t fully support all of epub3’s capabilities yet, or the advanced CSS selectors and XHTML structure we use, so we’re more interested in… -
the-strange-case-of-dr-jekyll-and-mr-hyde.epub, the compatible epub version of our ebook. This file is the raw source, plus various compatiblity fixes applied during our build process. If you don’t have a Kindle, this is the file you’ll be using to proofread. -
the-strange-case-of-dr-jekyll-and-mr-hyde.kepub.epubis the Kobo version of our ebook. You can copy this to a Kobo using a USB cable. -
the-strange-case-of-dr-jekyll-and-mr-hyde.azw3is the Kindle version of our ebook. You can copy this to a Kindle using a USB cable. -
thumbnail_xxxx_EBOK_portrait.jpgis a thumbnail file you can copy to your Kindle to have the cover art appear in your reader. A bug in Amazon’s software prevents the Kindle from reading cover images in side-loaded files; contact Amazon to complain.
Now, transfer the ebook to your ereader and start a cover-to-cover proofread.
What do we mean by “proofreading”?
“Proofreading” means a close reading of the text to try to spot any transcription errors or issues which the SEMoS says we must update. It’s typically not a line-by-line comparison to the page scans—that work was already done by the initial transcriber. Rather, proofreading is reading the book as you would any other book, but with careful attention to possible problems in the transcription or in your production. For some general tips on what to look out for when proofreading see the guide here.
-
-
Create the cover image
Now that you’ve read the ebook, you’re ready to find a cover image.
Cover images for Standard Ebooks books have a standardized layout. The bulk of the work you’ll be doing is locating a suitable public domain painting to use. See the Art and Images section of the SEMoS for details on assembling a cover image.
As you search for an image, keep the following in mind:
-
Cover images must be in the public domain. Thanks to quirks in U.S. copyright law, this is harder to decide for paintings than it is for published writing. You must provide proof of the public domain status of your selection to the S.E. in the form of a page scan of the painting from a book published before January 1, 1931, and your project manager must approve your selection before you can commit it to your repository. Our Artwork Database contains preapproved cover art options that you can browse by subject.
-
Find the largest possible cover image you can. Since the final image is 1400 × 2100, having to resize a small image will greatly reduce the quality of the final cover.
-
Your selection must in the style of a “fine art” oil painting, so that all Standard Ebooks have a consistent cover style.
-
The Standard Ebooks Editor-in-Chief has the final say on the cover image you pick, and it may be rejected for, among other things, poor public domain status research, being too low resolution, not fitting in with the “fine art” style, or being otherwise inappropriate for your ebook.
What can we use for Jekyll? In 1863 Hans von Marées painted an eerie self-portrait with a friend. The sallow, enigmatic look of the man on the left suggests the menacing personality of Hyde hiding just behind the sober Jekyll. It was reproduced in a book published in 1910.
You usually won’t have to edit the actual cover SVG file,
./images/cover.svg, because it’s automatically generated. All you have to do is resize and crop your cover art to 1400 × 2100 and move it to./images/cover.jpg.After you’re done with the cover, you’ll have four files in
./images/:-
cover.source.jpgis the raw image file we used for the cover. We keep it in case we want to make adjustments later. For Jekyll, this would be the raw portrait downloaded from Wikimedia. -
cover.jpgis the scaled cover image thatcover.svglinks to. This file is exactly 1400 × 2100. For Jekyll, this is a crop ofcover.source.jpg, and resized up to our target resolution. -
cover.svgis the full cover image including the title and author. This is auto-generated byse create-draft. -
titlepage.svgis the titlepage image auto-generated byse create-draft.
se build-imagestakes both./images/cover.svgand./images/titlepage.svg, converts text to paths, and embeds the cover artwork. The output is placed in./src/epub/images/, where you’ll commit it to your repo’s history.Once we built the images successfully, perform a commit.
git add -A git commit -m "Add cover image" -
-
Complete content.opf
content.opfis the file that contains the ebook metadata like author, title, description, and reading order. Most of it will be filling in that basic information, and including links to various resources related to the text. We already completed the manifest and spine in an earlier step.content.opfis standardized. See the Metadata section of the SEMoS for details on how to fill it out.The last details to fill out here will be the short and long descriptions, verifying any Wikipedia links that
se create-draftautomatically found, adding cover artist metadata, filling out any missing author or contributor metadata, and adding your own metadata as the ebook producer.Once you’re done, commit:
git commit -am "Complete content.opf" -
Complete the imprint and colophon
se create-draftput a skeletonimprint.xhtmlfile in the./src/epub/text/folder. Fill out the links to the transcription and page scans.There’s also a skeleton
colophon.xhtmlfile. Now that we have the cover image and artist, we can fill out the various fields there. Make sure to credit the original transcribers of the text (generally we assume them to be whoever’s name is on the file we download from Project Gutenberg) and to include a link back to the Gutenberg text we used, along with a link to any scans we used (from the Internet Archive or HathiTrust, for example).You can also include your own name as the producer of this Standard Ebooks edition. Besides that, the colophon is standardized; don’t get too creative with it.
Leave the release date unchanged, as
se prepare-releasewill fill it in for you in a later step.Once you’re done, commit:
git commit -am "Complete the imprint and colophon" -
Final checks
It’s a good idea to run
se typogrifyandse cleanone more time before running these final checks. Make sure to review the changes withgit difftoolbefore accepting them—se typogrifyis usually right, but not always!Now that our ebook is complete, let’s verify that there are no errors at the S.E. style level:
se lint .Once
se lintcompletes without errors, we’re ready to confirm that there are no errors at the epub level. (If you plan on submitting your project to Standard Ebooks and haven’t touched your repository in a while, make sure your toolset is up-to-date before linting.) We do this by invokingse buildwith the--check-onlyflag, which will runepubcheckto verify that our final epub has no errors, but won’t output ebook files, since we don’t need them right now.se build --check-only .Once that completes without errors, we’re ready to move on to the final step!
-
Initial publication
You’re ready to publish!
-
If you’re submitting your ebook to Standard Ebooks:
Contact the mailing list with a link to your GitHub repository to let them know you’re finished. A reviewer will review your production and work with you to fix any issues. They’ll then release the ebook for you.
Don’t run
se prepare-releaseon an ebook you’re submitting for review! -
If you’re producing this ebook for yourself, not for release at Standard Ebooks:
Complete the initial publication by adding a release date, modification date, and final word count to
content.opfandcolophon.xhtml.se prepare-releasedoes all of that for us.se prepare-release .With that done, we commit again using a commit message of
Initial publicationto signify that we’re all done with production, and now expect only proofreading corrections to be committed. (This may not actually be the case in reality, but it’s still a nice milestone to have.)git add -A git commit -m "Initial publication"Finally, build everything again.
se build --output-dir=$HOME/dist/ --kindle --kobo --check .
Congratulations! You’ve just finished producing a Standard Ebook!
-
{kind=link}